Accuracy: Can Retrieval-Augmented Generation (RAG) Truly Tame AI Hallucinations?

In the first part of this series, we explored what are hallucinations in Language Models (LLMs), unpacking their nature, origin, and the challenges they pose to businesses. To summarise, hallucinations are erroneous outputs generated by Language Models (LLMs) when faced with insufficient information, leading to inaccuracies and undermining the reliability of LLM-based applications.
The foundational LLMs, while versatile across domains, are inherently constrained by their training data and lack of access to private (or proprietary) data. This information gap is often cited as a primary cause of hallucinations. Additionally, the models don’t have a sense of what’s right or wrong, true or false like we do. Instead, they generate the most likely next word, based on the previous words in the input. It’s basically like making a best guess.
Given the widespread integration of LLMs in our lives and businesses—ranging from K-12 education to software development to customer service—this unreliability can have substantial (even harmful) consequences. When businesses deploy LLMs, there is an inherent expectation of near-perfect accuracy. If hallucinations are allowed to continue, the impacts on a business can include:
- Misleading information: Customer-facing LLM based chatbot can provide misleading information to the customer, potentially harming the business
- Brand value impact: The negative publicity from the misleading information can harm the brand and diminish their value.
- Ethical/legal/compliance risks: In regulated industries, accurate and reliable information is especially critical and hallucinations will lead to such exposure.
How can the hallucinations be detected, since they are so harmful. Some methods are as follows:
- Semantic analysis: The generated output can be evaluated for inconsistencies, nonsensical text or irrelevant information. This can only detect hallucinations for non-sensical text.
- Reference comparison: Output can be compared with reference dataset or ground truth to evaluate its accuracy. This only works if ground truth data is available and accessible.
- Human detection: Expensive option. Not always feasible for real-time applications.
Dealing With Hallucinations
So what can be done to reduce hallucinations? Some methodologies include:
- Enhance training data: Depending on the vertical of the application, the LLM can be re-trained on more data within the vertical.
- Improve the model: The models can be improved with factual updates using RLHF and Fine Tuning. This involves changing the model weights.
- Human-in-the-loop verification: A human validator should review and filter outputs, ensuring that the content aligns with desired outcomes.
- Automated monitoring: This will help guide accuracy improvements, reducing manual efforts.
Among these, methods 1 and 2 are time, cost and compute intensive and may not be agreeable to every business. Human verification beats the purpose of automation and breaks the real-time applications. Automated monitoring of hallucination is still in infancy and not sufficient for risk-averse businesses.
It will help if there is a way to enhance model training data, without the associated cost and time. This can be partly achieved through supplementing LLMs with external knowledge. Even though this does not re-train the model, it “guides” the model with additional “training data”. The idea that this technique can be used to mitigate hallucinations has gained traction. Retrieval-Augmented Generation (RAG) is a promising approach that aims to address this issue by integrating external documents into the model’s output generation process.
RAG To The Rescue
As the name suggests, RAG has two phases: retrieval and augmented generation. In the retrieval phase, algorithms search for and extract snippets of information relevant to the question. The source for this retrieval depends on the setting. Retrieval could be from documents on the Internet or a narrower set of private documents in the Enterprise. In the second phase, the question is augmented with the retrieved information and passed to the language model. The LLM uses the augmented prompt and its own internal representation of the training data to synthesize an answer.
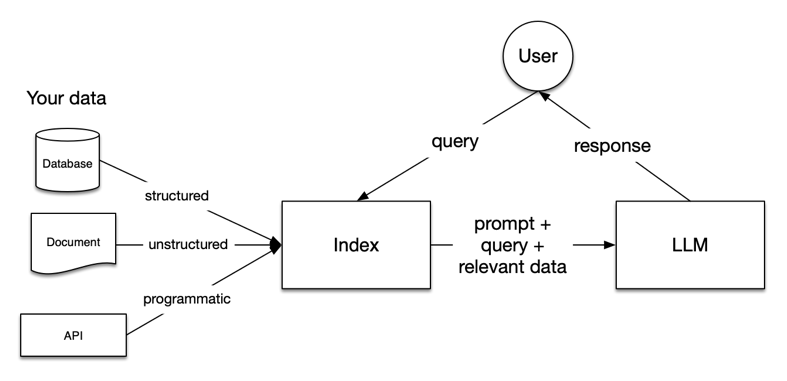
Image credit : docs.llamaindex.ai
Due to this context augmentation with external knowledge, we get the added benefit of the possibility of fact verification of the answer generated by the LLM. Overall, the benefits of the RAG-based approach include:
- Enhanced and updatable memory
- Source citations
- Cost reduction
- Hallucination reduction
Undeniably, RAG is useful and the way to go. Apart from the above benefits, it also lets enterprises that don’t want their documents used to train a model — say, companies in highly regulated industries like healthcare and law — to allow models to utilize those documents in a more private (and temporary) way.
Really Helpful?
It may come as a surprise but RAG is not a silver bullet that can eliminate hallucinations 100%.
RAG has its limitations as well. We can talk about the technical difficulties in implementing RAG in another series. Here we will focus on hallucination related issues alone.
Overall, RAG relies on the external data being provided through the documents. Is that sufficient to counter hallucinations? Agreed that it provides extra information (that is not part of the training data) which reduces the “need” for the LLM to confabulate.
The persistence of hallucinations is due to the following reasons:
- Quality of the supplemental data: Technically, the biases or errors in these data sources can influence the LLM’s response. However, since in an enterprise use case, the documents are controlled, this is not such a big factor.
- LLM creativity: The internal reasoning process of the LLM is unaffected by the supplemental information. Tendency to make “best guess” is not eliminated if and when faced with an out of syllabus question.
- Lack of validation and verification: RAG ends at generation and does not provide a way to validate the results against the context that was used for the generation. How was the adherence to the new context provided? How much was the recall?
Points 2 and 3 above need to be solved externally to the RAG pipeline to bring semblance of definiteness to the RAG based products.
Summary
In essence, are hallucinations here to stay? RAG even though promising, is no panacea. We do not yet have ready ways to really totally eliminate hallucinations. Even when RAG reduces the prevalence of errors, human judgment reigns paramount. And that’s no lie.
In the next part of this series, we will have an in-depth look at techniques and strategies for reducing hallucinations in rag systems.
Stay tuned for Part 3.
Leave a Reply