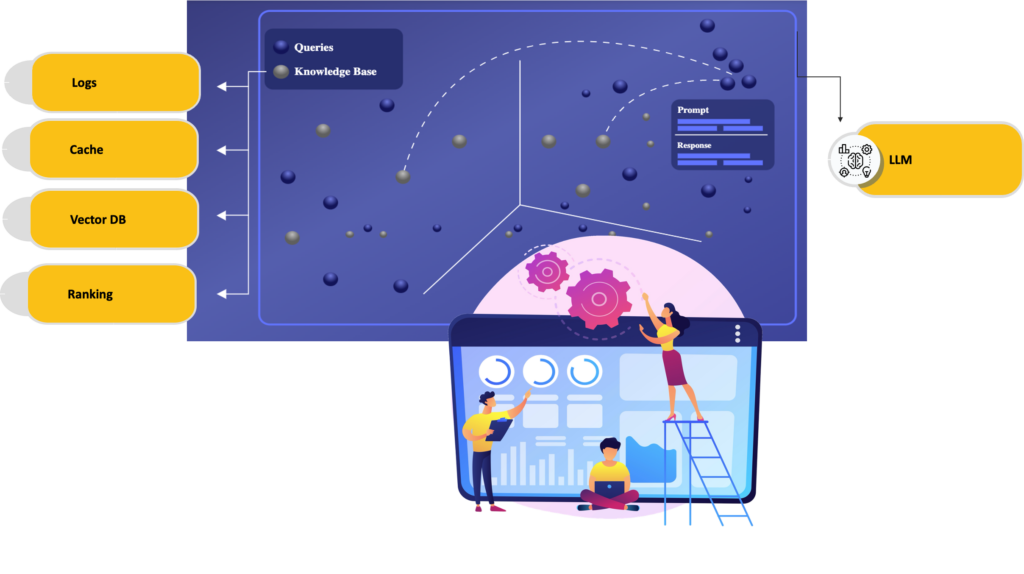
In the world of Generative AI, Retrieval-Augmented Generation (RAG) workflows have emerged as a powerful paradigm. By combining external knowledge retrieval with generative language models, RAG bridges the gap between static AI models and dynamic, contextually rich applications. However, implementing scalable, efficient, and secure RAG pipelines presents unique challenges. Enter the architecture that leverages both serverless and sidecar patterns to optimise the entire lifecycle of RAG workflows.
The Challenges in RAG Workflows
A typical RAG pipeline consists of three main stages:
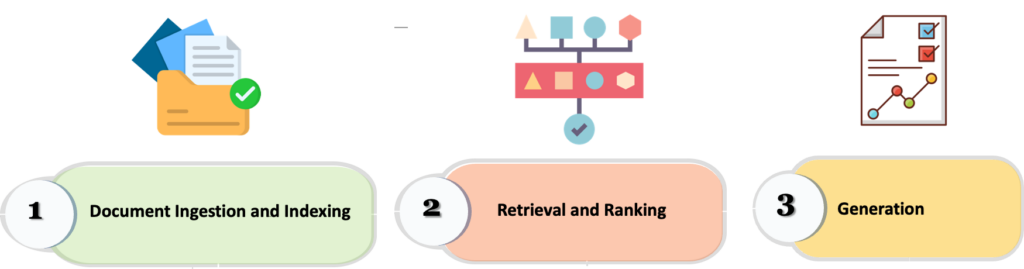
- Document Ingestion and Indexing: Regularly updating the knowledge base with fresh content
- Retrieval and Ranking: Fetching the most relevant documents from a vector database
- Generation: Feeding retrieved documents to a large language model (LLM) to generate responses
Each stage has distinct requirements. Document ingestion may occur sporadically, requiring scalability without maintaining idle infrastructure. Retrieval and ranking need low-latency responses, making caching essential. Generation workflows often require robust security for sensitive data. Addressing these needs demands an approach combining serverless and sidecar architectures.
Architecture Overview
The proposed architecture leverages the best of serverless and sidecar patterns:
Serverless for Document Ingestion and Pipeline Orchestration
Why Serverless?
- Elastic Scaling: Handles sporadic document ingestion workloads efficiently
- Cost-Effectiveness: Charges only for execution time, ideal for occasional updates
- Event-Driven Nature: Seamlessly integrates with triggers like new document uploads or database updates
How It Works:
- Document Processing: When new documents are uploaded (e.g., to an S3 bucket), a serverless function (e.g., AWS Lambda) is triggered
- Extract text using OCR or parsers
- Create embeddings using a pre-trained model
- Store embeddings in a vector database (e.g., Pinecone, Weaviate)
- Pipeline Orchestration: Serverless functions coordinate the RAG pipeline, ensuring retrieval, ranking, and generation steps execute sequentially or in parallel as needed
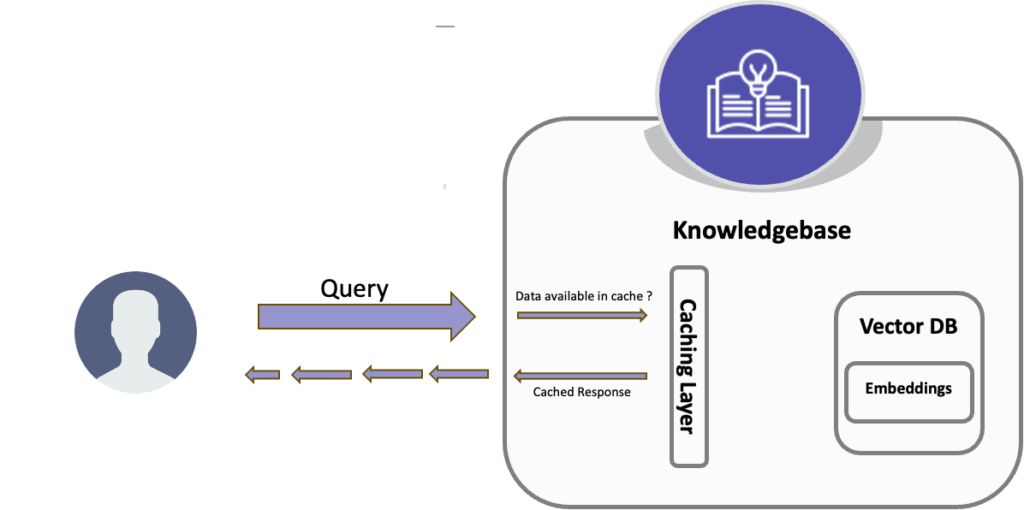
Sidecar for Caching, Latency Optimization and Security
Why Sidecar?
- Low-Latency Caching: Minimizes retrieval time by caching frequent queries and their results
- Enhanced Observability: Tracks pipeline performance, including retrieval scores and model latency
- Security Isolation: Manages encryption, token authentication, and secure communication independently
How It Works?
- Caching Layer: The sidecar (e.g., using Envoy or NGINX) caches results from the vector database and generative model, reducing redundant calls
- Security Handling: The sidecar ensures encrypted communication with external APIs and manages API keys or tokens without exposing them to the core application
- Monitoring and Logging: Provides detailed insights into query patterns, retrieval efficiency, and generation performance
Detailed Workflow
1. Document Ingestion
- A new document is uploaded to cloud storage (e.g., S3 bucket)
- Trigger: An event notification invokes a serverless function
- Processing:
- The document is parsed into text
- Embeddings are generated using an embedding model (e.g., OpenAI embeddings for SentenceTransformers)
- The embeddings and metadata are stored in a vector database
- Orchestration: The serverless function updates a status tracker, triggering downstream tasks if necessary
2. Retrieval and Ranking
- Query Handling: A user query reaches the RAG pipeline
- Sidecar Caching:
- The sidecar checks if the query or similar queries are cached
- If cached, the result is served immediately
- If not, the query proceeds to the vector database
- Retrieval:
- Relevant embeddings are fetched from the vector database
- A ranking model refines the results
- Caching Updates: The sidecar caches the latest query and results for future use
3. Generation
- Retrieved documents are sent to the LLM for response generation
- The sidecar ensures secure communication with the LLM API, managing token authentication and encrypting sensitive data
- Performance Metrics: The sidecar logs latency, API usage, and response quality for monitoring and optimization
Benefits of the Approach
1. Scalability and Cost Efficiency
- Serverless functions dynamically handle ingestion workloads without maintaining idle infrastructure
- Sidecars offload repetitive tasks like caching, reducing computational overhead on core services
2. Improved Latency and Performance
- Sidecars significantly reduce retrieval and generation latencies by caching frequent results and precomputing embeddings
3. Enhanced Security
- Sidecars isolate sensitive tasks like encryption and API token management, ensuring a secure and robust architecture
4. Observability and Debugging
- Sidecars provide granular logs and metrics for the RAG pipeline, facilitating real-time monitoring and debugging
Conclusion
By combining serverless and sidecar architectures, this approach addresses the unique demands of RAG workflows. Serverless functions provide scalable, cost-effective solutions for document ingestion and orchestration, while sidecars optimize latency, enhance security, and improve observability.
Together, they enable robust, efficient, and secure Generative AI applications that can scale with your needs.
Leave a Reply